马克·阿奇博尔德写的。
在上一篇文章中(在ChemSpider幕后)我们讨论了世界上最大的化学数据库之一在维护数据质量方面面临的一些挑战。当处理的记录远远超出人类的合理处理能力时,我们将自动过滤确定为一个关键工具。在这篇文章中,我们将更详细地讨论过滤是如何工作的,挑战是什么,以及人工干预所起的作用。
为了执行这个过滤,我们使用了一个开源数据处理平台KNIME。由活跃的化学信息社区开发的广泛KNIME节点允许我们对我们处理的数据提出化学特定的问题。新利手机客户端简单地说,与我们的标准匹配的输入化学结构被传递到下一个节点,而那些不匹配的化学结构则被写到错误文件中。在处理完所有结构之后,结果是一个已成功通过所有筛选器的结构文件,以及由于各种原因而被拒绝的多个(通常较小)结构文件。
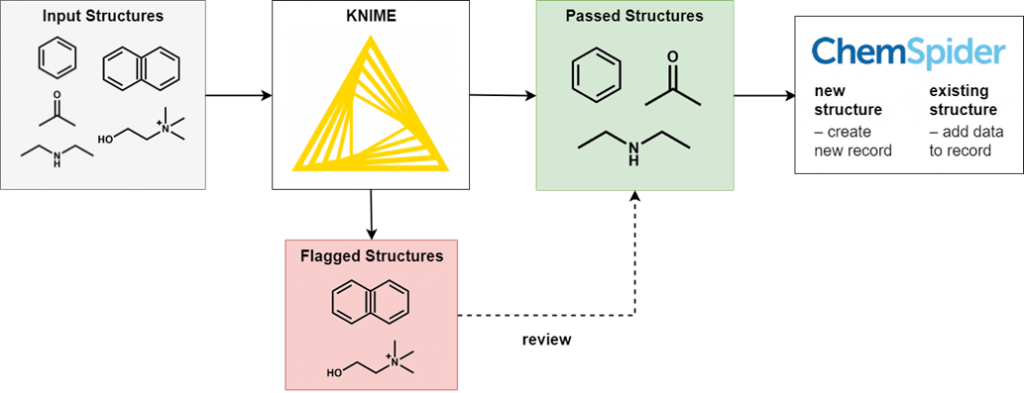
不可能完全检查所有生成的文件,因为这将消除自动处理的省时优势。但是,会抽查所有类型的输出文件的准确性,并迭代地改进筛选条件。某些输出文件具有很高的误报可能性,因此我们将对它们进行全面检查。
格式和标识符
提交的文件可以是几种不同格式之一。最常见的是SDF(结构数据文件,包含多个结构和相关数据字段的化学结构格式)。这种格式的优点是它包含二维或三维结构,因此我们可以立即开始处理文件,而不必将标识符转换为结构。这意味着我们所存放的最终结构更有可能与原始结构完全匹配。SDF格式的缺点是它是专门的,许多用户可能不熟悉它,或者没有软件来创建和显示文件。
我们还收到不同的电子表格格式(excel、csv、tsv),其结构编码为基于文本的符号系统,如SMILES或INCHI.这种格式的优点是不需要专门的软件(前提是提交者对化合物有SMILES或InChIs),缺点是结构在加工和沉积到ChemSpider之前需要转换成SDF。此外,这些格式包含有关原子及其连接性的信息,但缺少布局信息。这可能会引入错误,因为不同的结构绘图包对这些结构的解析略有不同,从而导致对最终沉积结构的更改。
筛选条件
根据我们的经验和化学知识,我们判断化学结构的标准是确定的化学规则和不太明确的“经验法则”的混合。下面是这两种情况的例子。
空结构,查询原子和错误的价
第一个过滤器是最简单的——ChemSpider是一个以结构为中心的数据库,因此不可能存放任何缺少结构的输入条目。
类似地,每个ChemSpider记录都需要一个单独定义的化学结构,因此我们排除使用查询原子来表示变量原子或附着点的任何内容。
另一个简单的过滤器是排除原子具有无效价的结构。
电荷不平衡
一般来说,ChemSpider中的条目应该表示真实世界中的可分离化合物。这意味着我们过滤掉总电荷为非零的结构。然而,我们对某些例子做了例外,在这些例子中,反离子通常不重要,仅考虑带电物种是有用的,例如胆碱(ChemSpider记录).
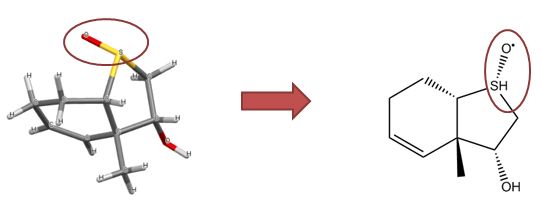
含有未定义立体中心的结构
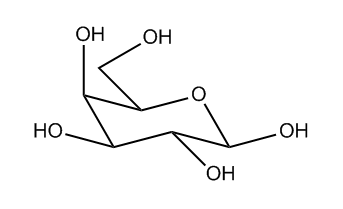
光是未定义的立体中心并不代表化学误差。然而,像下面所示的结构(没有任何确定的立体中心的胆固醇)经常出现,虽然化学上有效,但它们极不可能代表预期的结构。
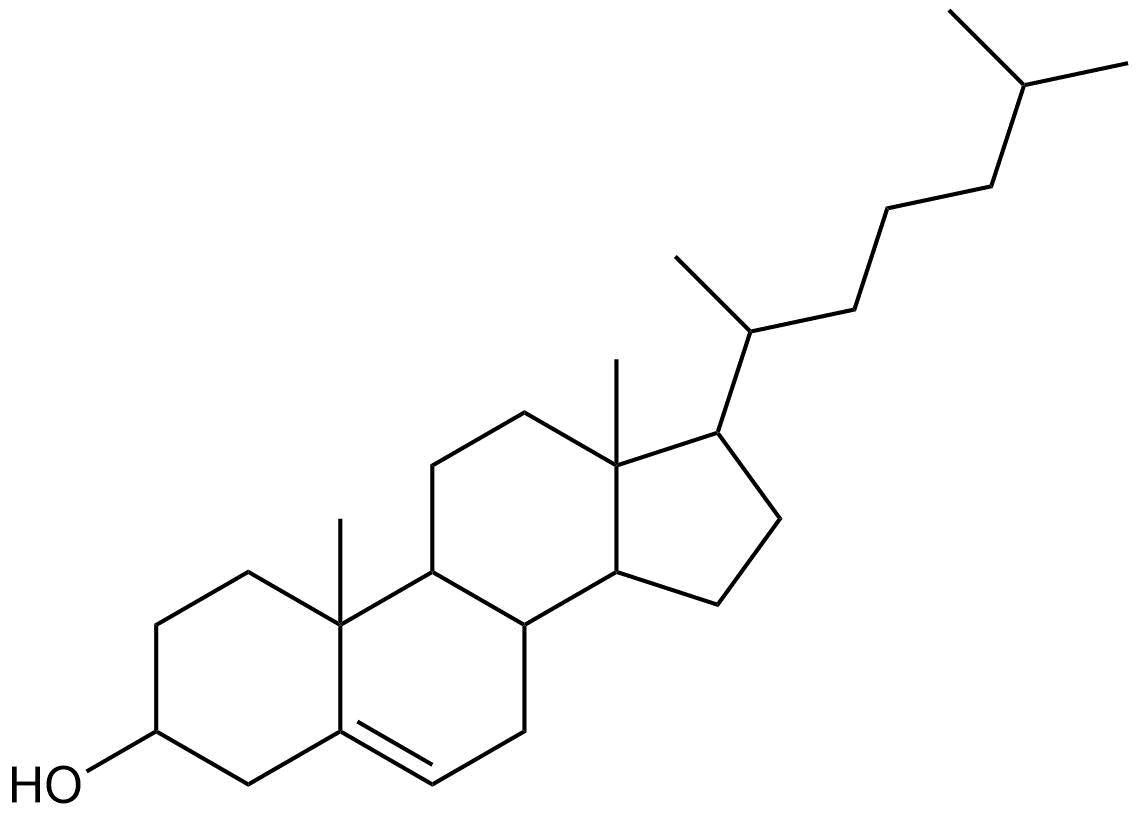
胆固醇骨架无立体新利手机客户端
因此,我们有一个经验法则,排除含有两个以上未定义立体中心的结构。这不是一条硬性规定,而是试图在排除上述结构和包括未定义立体中心是有意和正确的结构之间取得平衡。
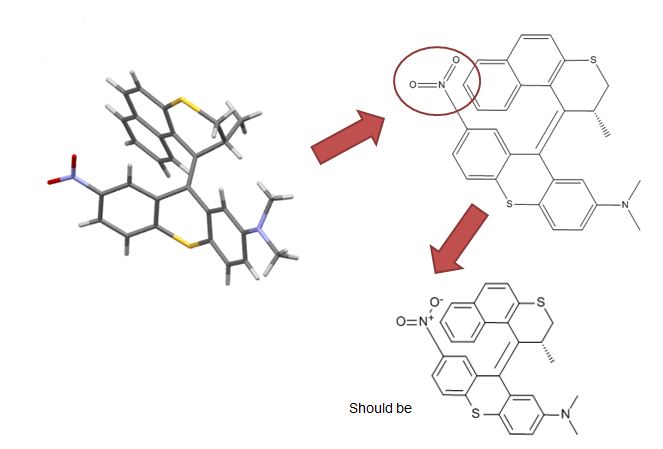
未定义立体中心的计数(通过检查InChI确定)有时包括常规排除立体化学楔子的情况。实例包括核酸与磷酸没有楔和金刚组没有明确的立体 - 这是不寻常的绘制这些化合物与楔子,而用户很少会在其搜索中使用挖起杆。新利手机客户端这些潜在的误报被筛选出来并进行人工审查。然后馆长可以决定是否将其列入沉积,提高了过滤器的整体精度。
包含许多组件结构
这是经验的另一个规则 - 有一个正确的描述化学物质能有多少独立的组件没有上限。然而,从经验中我们发现,不包括结构与四个以上的独立组件去除大部分明显荒谬的条目(例如试图描绘了合金),同时保留了大部分正确的条目。
当应用此规则,药物分子代表的假阳性的主要来源,因为它们往往是多重的水合物和/或具有多个抗衡离子的盐(例如盐酸伊立替康三水).是水合物或包含公共药用盐排除的结构标记为人工审核。
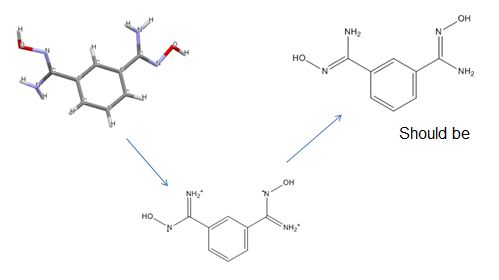
过滤器的同义词
该过滤器相比较分配给给定的结构与它的分子式和执行某些“常识”检查同义词。例如,一个相对频繁的误差相关联的盐形式的名称(例如,mozavaptan盐酸盐)与游离碱的结构(mozavaptan).在这种情况下,过滤器去除含有“盐酸”,因为分子式不包含氯的同义词。
SMARTS
SMARTS(维基百科页面)是描述一般化学结构的一种方式。它基于SMILES,但是具有附加的特征允许可变的链长,键的数量,氢的数目,可变键序,或者在一个站点一个以上的潜在元素的规范。
我们使用SMARTS识别的结构共同的错误功能。这些包括:
- 叠氮化物,并用五价氮描绘重氮基
- A“浮动”烷烃未连接到主结构上(可能由意外点击在绘图程序引起的)
- 描绘为质子化羧酸与元素金属原子金属羧酸盐
- 六氟磷酸盐(以及类似的物质)描绘为五氟化磷和一个单独的氟离子
傻笑
假笑是SMILES的进一步延伸到描绘反应。我们不会用它来代表真实的反应,但定义的结构转换 - 让我们来解决,可以通过打破和创造债券来解决简单的结构错误。
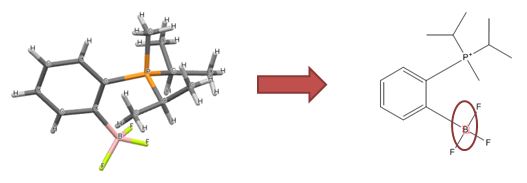
一个例子是连接电荷分离格氏试剂,得到更准确的描述:
重新连接格氏试剂
金属有机化合物
以机器可读格式编码的有机金属结构的困难是有据可查的(J.化学。天道酬勤。模型。51,12,3149-3157).有一个持续的IUPAC项目延长INCHI的功能但就目前而言,挑战依然存在。
每ChemSpider记录基本上是基于一个INCHI,所以我们是通过电流限制的约束。这意味着我们可以不描绘的配位键或具有非整数顺序债券 - 绘制被解释为与一个电子贡献的每个原子的标准共价键的任何键。
虽然我们一般不能代表方式有机金属结构人类化学家愿意,我们还是尝试选择从各种可能的妥协“至少错”结构。
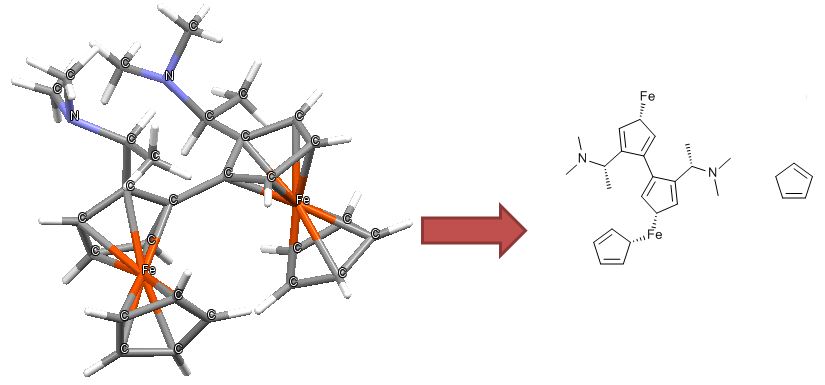
二茂铁是这个问题的一个典型的例子,并说明了几个我们要考虑的问题。二茂铁显示在下面一些常见的方式吸引用户(还有更多)。
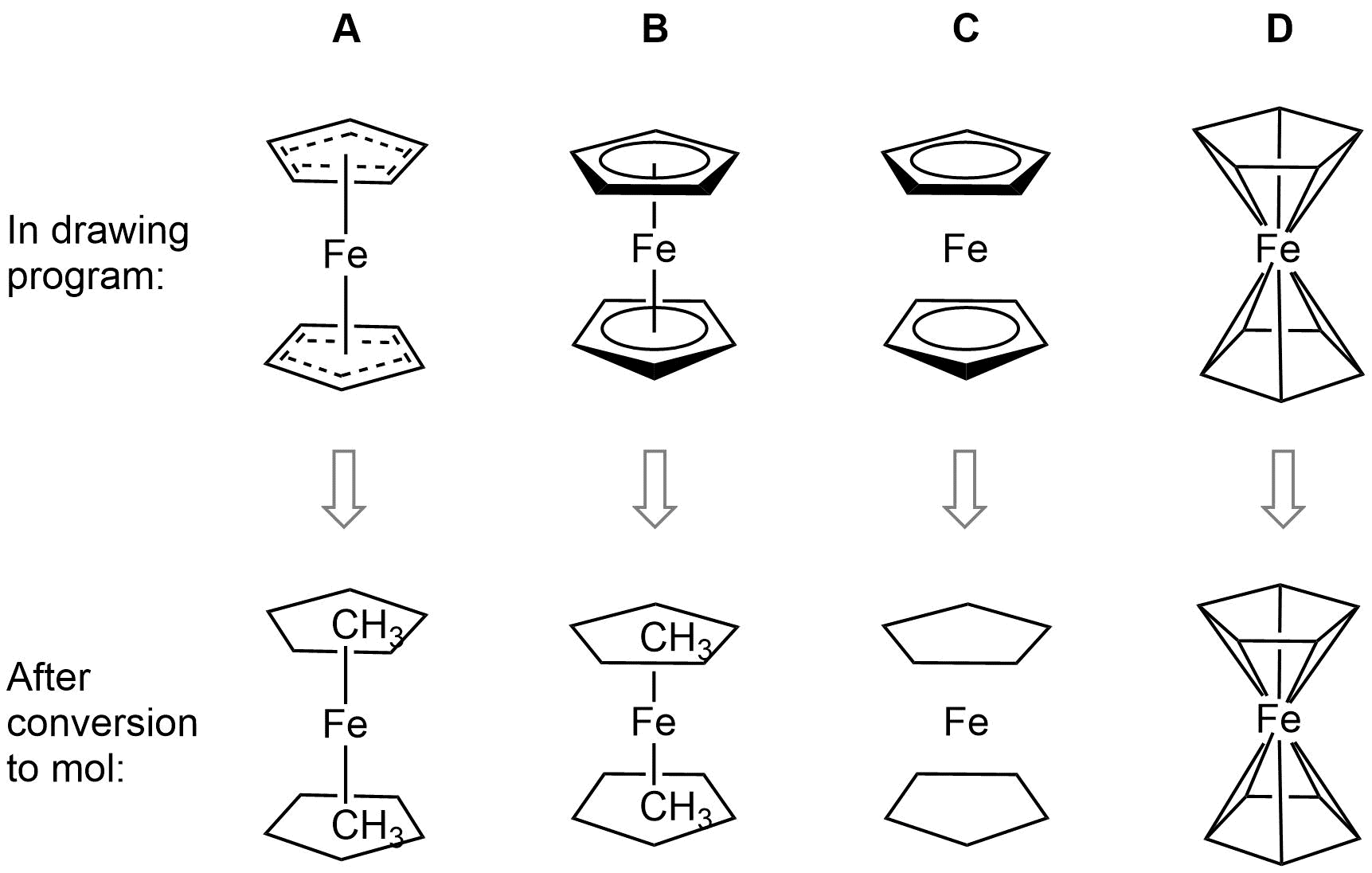
转换的二茂铁结构,以摩尔格式可以引入分子式中的错误,键级或价
为了大多数的化学绘图程序的扩展功能所示结构趁代表的方式,是有吸引力的,容易理解的人化学家二茂铁的粘接。不幸的是,一旦转移到简化,但普遍摩尔格式,其中的一些功能将丢失,从而导致无意义的结构。虽然结构d是不变的,这表示具有其他的问题:对Fe化合价不正确并且没有环戊二烯基配的芳香性表示。
我们的方法,使我们能够描绘二茂铁和相关结构在ChemSpider,其中没有一个得到接合的精确表示,或者将满足无机化学家的视图的数量有限。然而,我们可以选择的可能妥协的“最不坏”,让机器可读性:
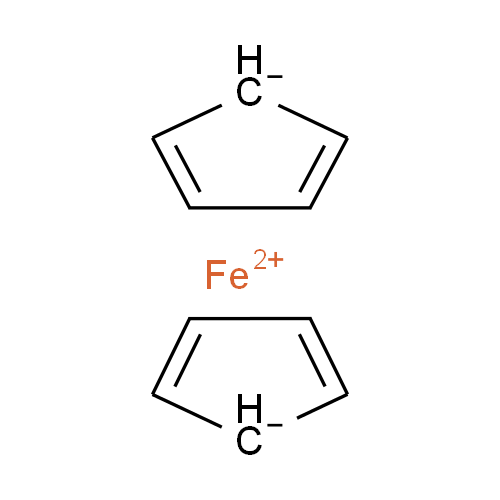
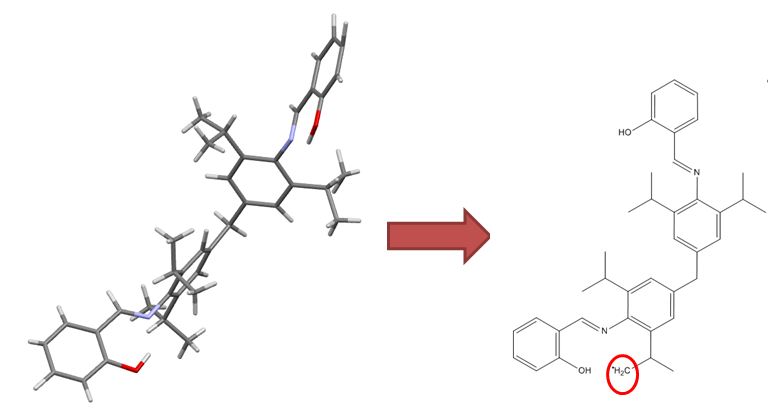
我们妥协
虽然这种结构(ChemSpider记录)不捕获二茂铁的哈普托数和在单个碳的电荷定位不准确,它保留正确整体费用和化合价而没有示出的配位体如σ-键连接的。
更一般地,我们运用一些规则和转换,以规范有机金属结构的表示。许多的这些规则涉及选择是否描绘了金属 - 碳(或金属 - 杂原子),为共价或离子,这取决于金属和配体的性质。此外,机器可读结构的限制范围内工作时,妥协是必要的,但我们试图“更离子”和“多价”的债券进行分类。下面是一些例子:
- 来自组1和2族的金属氧断开
- 连接氧气所有金属
- 选自钠,钾和钙断开碳
- 连接碳基团11和12族金属,p区的金属和准金属的一些
正如预期的那样,这样的一般规则无法在某些情况下。因此,我们要盖例外,这是我们反复改进额外的,更具体的规则。
但是,这些错误仍然会出现在ChemSpider!
目前滤波描述仅适用于新的数据进入ChemSpider。经过多年构建的完整ChemSpider数据库当然包含这里描述的每个错误的示例。为了修复这些遗留错误,我们打算通过相同的质量过滤器运行整个数据库。这是一个具有一些特定挑战的重要任务:需要人工检查的文件变得大了几个数量级,处理时间和内存/CPU开销很高,数据集越大,我们越有可能遇到误报。为了应对这些挑战,我们正在花时间对新取证的过程进行改进,并通过过滤器定期运行完整的ChemSpider数据库的子集来检查进展情况。我们知道你需要访问你可以信任的数据,所以我们想确保我们做对了。随着项目的进展,我们将继续更新您的信息,请继续关注!